LSM-Tree
LSM-Tree(Log Structrued-Merge Tree)是很多NoSQL的底层引擎实现,比如LevelDB,HBase,Cassandra等等。
LSM-Tree是一种分层,有序,面向磁盘的结构,主要利用的是,磁盘顺序写的速度比随机写高出很多(两个数量级)。比如Log顺序写入的方法,通过append追加写入。这种结构写入速度很快,但是缺点是它牺牲了部分读性能,对随机读取不友好,所以这种结构更适用于读少写多的情景。例如:
数据是被整体访问的,如/数据库的WAL机制。
数据是通过文件偏移量访问到的,如Kafka。
SSTable
SSTable(Sorted String Table,排序字符串表)是LSM-Tree中核心的数据结构,具有持久化,有序,不可变的特点。这种结构的好处:
内存中只需要记录稀疏索引,减少了内存索引的大小
查询操作无需扫描整个日志,减少了磁盘IO
支持区间查询
密集索引中每一个搜索码值都对应一个索引值,密集索引决定了表的物理排序,一个表只有一个物理排序,所以一个表只能创建一个密集索引。占用存储空间更大,搜索时间更短。
稀疏索引中只为某些搜索码值创建索引值,占用的存储空间较小,搜索时间更长。
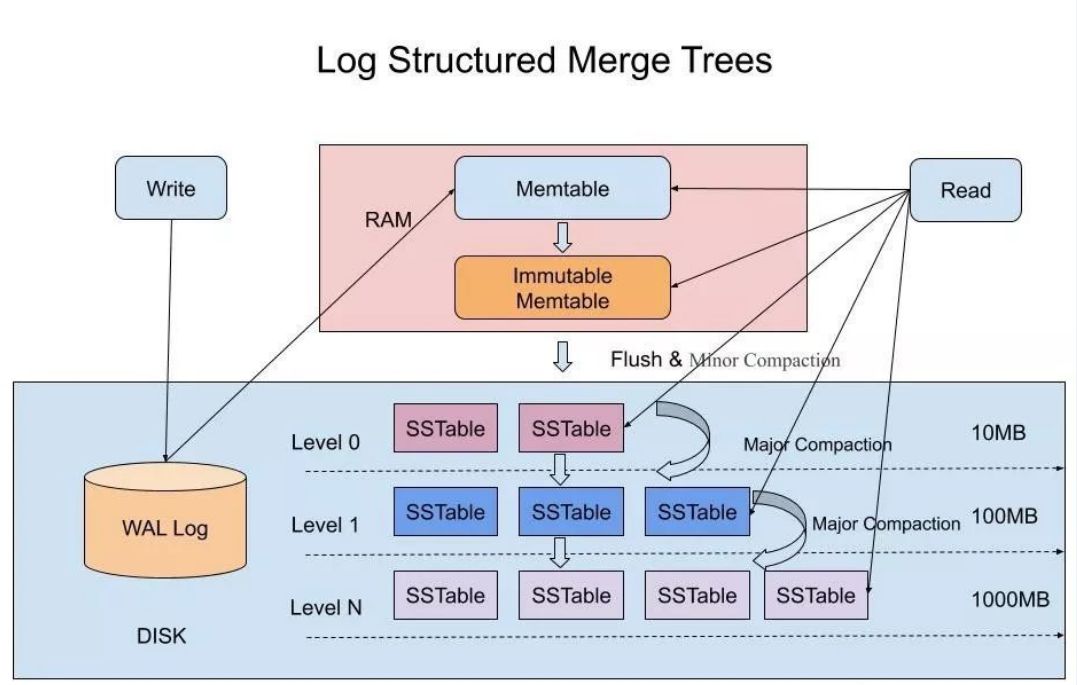
在LSM-Tree中写入数据的步骤如下:
收到写请求时,会先把数据记录到WAL上,用作故障恢复。
写完WAL后,写入内存中的SSTable中(删除的话是用墓碑标记),也成为Memtable。
Memtable达到一定的大小后会在内存中被冻结,不可变,同时生成一个新的Memtable服务。
被冻结的Memtable写入硬盘上的SSTable,这个步骤也叫做Minor Compaction。需要注意的是,L0层的SSTable是没有进行合并的,所以这里的key range在多个SSTable中可能出现重叠。
当每层的磁盘上的SSTable的体积超过一定的大小或者个数,也会周期的进行合并。这个步骤也称为Major Compaction,这个阶段会真正的清除掉被标记删除掉的数据以及多版本数据的合并,避免浪费空间。由于SSTable都是有序的,也可以直接采用merge sort进行高效合并。
在LSM-Tree中又是如何读取数据的呢?
- 答案是,首先在内存中进行寻找,如果没有查询到,就逐个Level进行查找。
所以,在寻找的时候的最坏情况是,需要把所有的Level都查询一遍。如果Level的层数多,应该如何进行优化呢?
压缩
SSTable可以启动压缩功能,不过不是整个SSTable一起压缩,是根据localiy将数据分组后进行压缩。
缓存
SSTable在写入磁盘后,除了Compaction之外,是不会变化的,所以我可以将Scan的Block进行缓存,从而提高检索的效率。
索引
通过布隆过滤器判断一个SSTable是否存在某个key,减少不必要的磁盘扫描。
合并
Compaction可以提高磁盘利用率,但是十分消耗CPU和磁盘IO。
和B+树的比较
在数据的更新和删除方面,B+树支持原地更新删除数据,LSM-Tree只能追加写入。
LSM-Tree适用于写多读少的情况,而B+树的设计在读取数据的时候更快,在修改数据的时候,因为涉及索引的维护,页分裂合并等情况,性能会降低。
实现
SSTable的文件格式
分为三个区:数据区,稀疏索引区,文件索引区。根据命令,而不是数据进行存储(与持久化有关)。
写入时 key 会按照任意顺序出现,那么如何保证 SSTable 中的 key 是有序的呢?一个简单方便的方式就是先保存到内存的红黑树(通过TreeMap实现)中,红黑树是有序的,然后再写入到日志文件里面。